
【新唐人北京時間2023年12月16日訊】中國互聯網科技公司巨頭字節跳動為了「抄近道」,違規使用OpenAI的技術來開發自家大模型。OpenAI宣布暫停字節跳動的GPT帳戶使用權限,並對其「不正當行為」展開調查。
12月15日,美國科技新聞及媒體網絡The Verge報導,字節跳動在未經OpenAI允許的情況下,一直在祕密使用 OpenAI 的技術來開發自己的競爭性大語言模型(LLM)。這些技術被應用於字節跳動的推薦算法、語音識別等領域,為公司帶來了巨大的商業利益。

報導說,字節跳動的內部文件證實,該公司代號為「種子計劃」(Project Seed)基礎大語言模型項目中,幾乎在每個開發階段,包括訓練和評估模型,都依賴 OpenAI API 來開發,而這些做法直接違反了OpenAI 的相關規定。
OpenAI 的服務條款有明文規定,該公司所輸出的模型不能被用於「開發任何與我們的產品和服務競爭的 AI 模型」。字節跳動通過微軟購買了 OpenAI 的訪問權限,但是微軟也制定了與 OpenAI 同樣的政策。
報導還指出,字節跳動的員工在內部溝通平台上的對話顯示,相關員工非常清楚這麼做的後果。他們曾在群組中討論如何通過「資料脫敏」來掩飾相關證據的問題。
這種濫用行為非常猖獗,以至於 「種子計劃」的員工在使用過程中經常達到 OpenAI API 的最大訪問上限。
字節跳動大約在幾個月前下達了「模型開發的任何階段停止使用 GPT 生成的文本」的命令。而正是在這個時候,字節跳動發布了自家大語言模型「豆包」(Doubao)。
資料顯示,字節跳動的「種子計劃」大約在一年前啟動,目前主要研發兩個產品,一個是在國內已經上線的「豆包」;另一個是針對商業用戶的聊天機器人平台,目前正在開發中。
The Verge的報導還提到,一位對字節跳動內部情況有一手消息的人透露說,「他們(指字節跳動的員工)說,他們想確保一切(行為)都是合法的,但他們實際上只是不想被抓住把柄。」
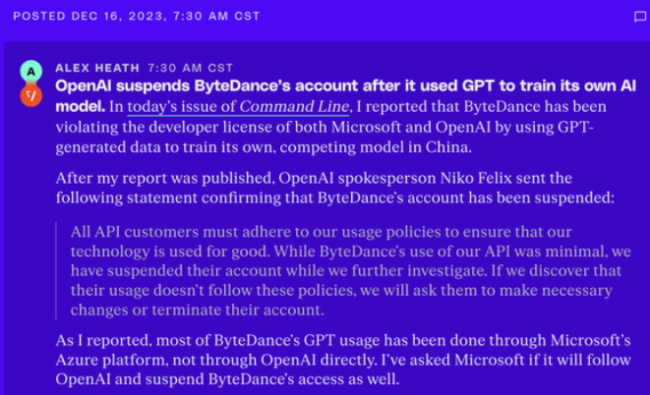
在上述消息發表出來後,OpenAI 的發言人尼克・菲利克斯(Niko Felix)發表聲明說,所有 API 客戶必須遵守OpenAI的使用政策,以確保相關技術不會被濫用。目前,OpenAI公司已經暫停了字節跳動的GPT帳戶使用權。
菲利克斯表示:「我們會進一步調查。如果我們發現他們的使用不符合規則,我們將要求他們進行必要的更改或終止他們的帳戶。」
當地時間12月16日下午,字節跳動發言人針對The Verge的報導回應稱,在「種子計劃」的早期開發中,字節跳動曾把GPT 生成的數據用於注釋模型,但這些數據已經在今年年中的時候「從字節跳動的訓練數據中刪除」。聲明並稱,「我們在非中國市場使用GPT支持我們的產品和功能;但在中國市場,使用我們自主開發的模型來支持豆包」。
此事曝光後,不僅在科技圈引起廣泛關注,也在中國社交媒體上引發討論。
有中國網友留言嘲諷字節跳動的回應:「偷過,現在沒有了。」另一位網友則評論說:「你以為彎道超車是怎麼超的?」還有網友調侃道:「一邊被別人卡脖子,一邊又說自己遙遙領先,是不是有點搞笑?」



(記者唐迪綜合報導/責任編輯:雲濤)




























